
Implementa playbooks de respuesta a incidentes basados en el marco NIST 800-61. Fases, procedimientos, automatización y mejores prácticas para organizaciones.
Los playbooks de respuesta a incidentes son los documentos operativos que transforman la teoría de la gestión de crisis en acciones concretas, reproducibles y medibles. En un entorno donde el tiempo medio de detección de una brecha de seguridad supera los 200 días según el informe anual de IBM, disponer de procedimientos de respuesta bien definidos y ensayados puede significar la diferencia entre un incidente controlado y una catástrofe organizacional. Este artículo examina cómo construir playbooks efectivos alineados con el marco NIST SP 800-61, el estándar de referencia en respuesta a incidentes de ciberseguridad.
El marco NIST SP 800-61
La publicación especial 800-61 del Instituto Nacional de Estándares y Tecnología de EE.UU. (NIST), titulada Computer Security Incident Handling Guide, establece un marco estructurado para la respuesta a incidentes que ha sido adoptado como referencia por organizaciones de todo el mundo. Su enfoque se articula en cuatro fases fundamentales que constituyen la columna vertebral de cualquier playbook de respuesta:
Fase 1: Preparación
La preparación es la fase más importante y, paradójicamente, la más frecuentemente descuidada. Una preparación adecuada incluye los siguientes elementos:
- Equipo de respuesta a incidentes (CSIRT): Definir las funciones, responsabilidades y autoridad del equipo, incluyendo la composición multidisciplinar (seguridad, TI, legal, comunicaciones, dirección).
- Políticas y procedimientos: Documentar las políticas de respuesta a incidentes, los criterios de clasificación de severidad y los procedimientos de escalamiento.
- Herramientas y recursos: Disponer de las herramientas técnicas necesarias (SIEM, EDR, forensic workstations, máquinas aisladas) y de los recursos logísticos (comunicaciones de emergencia, acceso fuera de banda).
- Comunicaciones: Establecer canales de comunicación seguros y alternativos para la coordinación durante un incidente, independientes de la infraestructura potencialmente comprometida.
- Contactos y acuerdos: Mantener una lista actualizada de contactos internos y externos (proveedores, CERT, fuerzas de seguridad, asesoría legal) y acuerdos de nivel de servicio para soporte de emergencia.
- Formación y simulacros: Realizar formación periódica del equipo y simulacros (tabletop exercises) que pongan a prueba los playbooks en escenarios realistas.
Fase 2: Detección y análisis
La detección temprana es crítica para limitar el impacto de un incidente. Los playbooks deben definir procedimientos específicos para:
- Fuentes de detección: Alertas del SIEM, detecciones del EDR, notificaciones de usuarios, informes de terceros, inteligencia de amenazas y hallazgos durante auditorías.
- Clasificación del incidente: Categorizar el incidente según su tipo (malware, phishing, acceso no autorizado, DDoS, exfiltración de datos, etc.) y su severidad (crítica, alta, media, baja).
- Análisis inicial: Recopilar y preservar evidencia, determinar el alcance potencial, identificar los sistemas afectados y evaluar el vector de ataque inicial.
- Notificación: Comunicar el incidente a las partes interesadas según los protocolos definidos, incluyendo los requisitos legales de notificación bajo normativas como el RGPD.
Fase 3: Contención, erradicación y recuperación
Estas tres subfases se ejecutan de forma secuencial y configuran el núcleo operativo del playbook:
Contención
El objetivo de la contención es limitar el alcance y el daño del incidente. Las estrategias de contención deben equilibrar la necesidad de detener la amenaza con la necesidad de preservar evidencia y mantener la operatividad del negocio:
- Contención a corto plazo: Aislamiento inmediato de sistemas comprometidos, bloqueo de direcciones IP maliciosas, desactivación de cuentas comprometidas, segmentación de red de emergencia.
- Contención a largo plazo: Parcheo de vulnerabilidades explotadas, implementación de reglas de firewall adicionales, reforzamiento de la autenticación, monitorización intensiva de los sistemas afectados.
Erradicación
La erradicación elimina completamente la presencia del atacante en los sistemas:
- Eliminación de malware, backdoors y herramientas del atacante.
- Rotación de todas las credenciales que puedan haber sido comprometidas.
- Revocación de certificados y tokens de acceso comprometidos.
- Reconstrucción de sistemas desde imágenes limpias cuando sea necesario.
- Verificación de que no persistan mecanismos de acceso no autorizado.
Recuperación
La recuperación restaura los sistemas a su operación normal de forma segura:
- Restauración de datos desde backups verificados (asegurando que los backups no están comprometidos).
- Reconexión gradual de sistemas a la red, con monitorización intensiva.
- Verificación de la integridad de los sistemas restaurados.
- Restablecimiento de servicios para usuarios y clientes.
- Monitorización reforzada durante un período extendido para detectar posibles reinfecciones.
Fase 4: Actividad post-incidente
La fase post-incidente es donde las organizaciones aprenden y mejoran. Los procedimientos incluyen:
- Informe de lecciones aprendidas: Documentar qué funcionó, qué falló y qué puede mejorarse, sin buscar culpables sino mejoras sistémicas.
- Revisión de playbooks: Actualizar los playbooks basándose en la experiencia del incidente real.
- Análisis forense adicional: Si es necesario, realizar análisis forenses más profundos que los realizados durante la respuesta de emergencia.
- Medidas correctivas: Implementar las mejoras identificadas en la revisión de lecciones aprendidas.
- Métricas: Calcular métricas clave como tiempo de detección (MTTD), tiempo de contención (MTTC) y tiempo de recuperación (MTTR).
Anatomía de un playbook de respuesta a incidentes
Un playbook bien estructurado debe contener los siguientes elementos:

Metadatos del playbook
- Identificador único y versión del documento.
- Tipo de incidente que cubre (por ejemplo, PLAYBOOK-RANSOMWARE-001).
- Clasificación de severidad y criterios de activación.
- Fecha de última revisión y propietario del documento.
- Aprobación por parte del responsable del CSIRT.
Procedimientos paso a paso
Cada procedimiento debe ser lo suficientemente detallado para que un miembro del equipo con la formación adecuada pueda ejecutarlo sin necesidad de consultar fuentes externas. Esto incluye comandos específicos, rutas de archivo, parámetros de configuración y criterios de decisión claros para cada bifurcación del proceso.
Árboles de decisión
Los playbooks deben incluir diagramas de flujo o árboles de decisión que guíen al respondedor ante diferentes escenarios. Por ejemplo, si el ransomware se detecta en un servidor de base de datos versus en una estación de trabajo, los pasos de contención y recuperación serán diferentes.
Plantillas de comunicación
Incluir plantillas pre redactadas para las comunicaciones más críticas: notificación interna a dirección, notificación a la Agencia Española de Protección de Datos, comunicación a clientes afectados y declaraciones para medios de comunicación.
Checklists de verificación
Listas de comprobación para cada fase que permitan al respondedor verificar que no ha omitido ningún paso crítico, especialmente bajo la presión de un incidente en curso.
Playbooks esenciales por tipo de amenaza
Toda organización debería desarrollar como mínimo los siguientes playbooks:
Playbook de ransomware
El playbook de ransomware debe cubrir la identificación de la cepa, el aislamiento inmediato para prevenir la propagación lateral, la preservación de evidencia forense, la evaluación de las opciones de recuperación (backup vs. descifrado) y los procedimientos de comunicación con las partes afectadas. Es particularmente importante definir claramente la postura de la organización respecto al pago del rescate, que nunca debe decidirse durante el incidente.
Playbook de phishing y compromiso de credenciales
Este playbook debe abordar la identificación del alcance del phishing (cuántos usuarios recibieron el correo, cuántos hicieron clic, cuántos introdujeron credenciales), el bloqueo de las URLs y dominios maliciosos, el reset inmediato de las contraseñas comprometidas, la revocación de sesiones activas y la monitorización de actividad sospechosa en las cuentas afectadas.
Playbook de acceso no autorizado
El playbook de acceso no autorizado debe incluir procedimientos para la identificación del vector de entrada, la determinación del alcance de la intrusión, la identificación de datos accedidos o exfiltrados, el aislamiento del atacante y la verificación de que no se han dejado puertas traseras.
Playbook de DDoS
El playbook de DDoS debe definir los umbrales de activación, los procedimientos de mitigación con el proveedor de infraestructura o CDN, las comunicaciones con ISP upstream y los planes de comunicación con usuarios y clientes.
Playbook de exfiltración de datos
Este playbook debe cubrir la identificación de los datos afectados, la evaluación del impacto regulatorio (especialmente bajo RGPD), los procedimientos de notificación a la AEPD y a los afectados, y las medidas de contención para prevenir una mayor exfiltración.
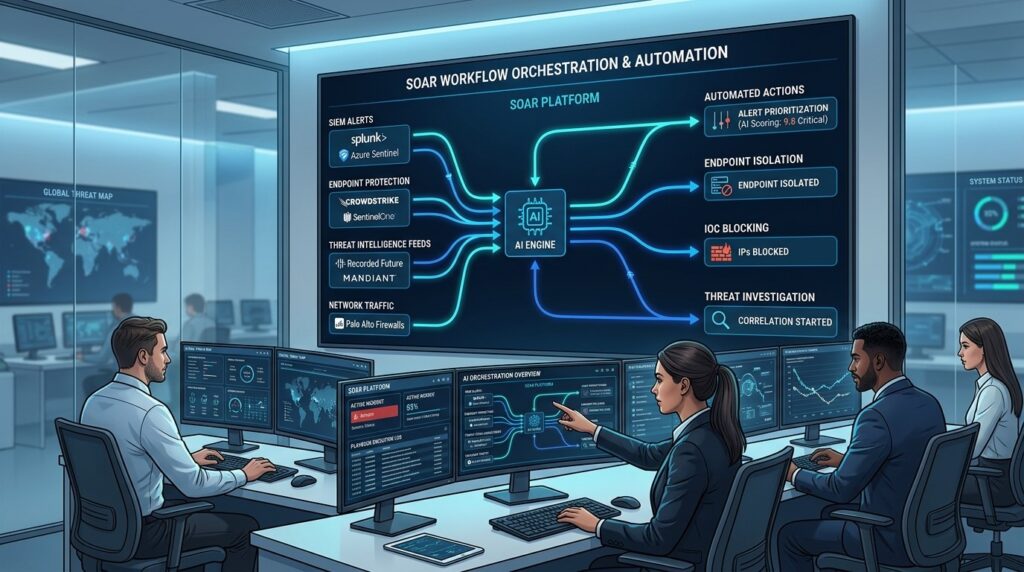
Automatización de la respuesta a incidentes
La automatización es clave para reducir los tiempos de respuesta en un panorama donde los atacantes operan a velocidad de máquina. Las plataformas SOAR (Security Orchestration, Automation and Response) permiten implementar playbooks automatizados que ejecutan acciones de contención de forma inmediata:

- Cierre automático de alertas falsas positivas: Reducir la fatiga del analista filtrando automáticamente alertas que cumplan criterios predefinidos de falsos positivos.
- Aislamiento automático de endpoints: Cuando el EDR detecta malware de alta confianza, el playbook puede aislar automáticamente el endpoint de la red mientras se realiza la investigación.
- Bloqueo automático de indicadores: Integrar feeds de inteligencia de amenazas con firewalls y proxies para bloquear automáticamente IOC identificados.
- Notificación automatizada: Enviar alertas al equipo de respuesta y a los responsables según el nivel de severidad del incidente.
- Recopilación automática de contexto: Al detectar un incidente, recopilar automáticamente información relevante de múltiples fuentes (SIEM, EDR, logs, inventario de activos).
Herramientas como Splunk SOAR, Palo Alto XSOAR, Swimlane y TheHive permiten implementar estos playbooks automatizados, reduciendo el tiempo medio de respuesta de horas a minutos.
La automatización debe complementar, no reemplazar, el juicio humano. Los playbooks automatizados deben incluir puntos de decisión donde un analista humano deba aprobar las acciones antes de su ejecución, especialmente aquellas que puedan tener impacto en la operatividad del negocio.
Métricas y mejora continua
La efectividad de los playbooks debe medirse a través de métricas objetivas que permitan la mejora continua:
- MTTD (Mean Time to Detect): Tiempo medio desde el inicio del incidente hasta su detección.
- MTTC (Mean Time to Contain): Tiempo medio desde la detección hasta la contención efectiva.
- MTTR (Mean Time to Recover): Tiempo medio desde la contención hasta la recuperación completa.
- Tasa de falsos positivos: Porcentaje de alertas que resultan no ser incidentes reales.
- Cumplimiento del playbook: Porcentaje de pasos del playbook que fueron ejecutados correctamente durante incidentes reales.
- Resultados de simulacros: Tiempos de respuesta y hallazgos durante ejercicios de tabletop.
Integración con el marco normativo español
Las organizaciones españolas deben alinear sus playbooks de respuesta a incidentes con los requisitos del marco normativo nacional:
- ENS (Esquema Nacional de Seguridad): El ENS, regulado por el Real Decreto 311/2022, exige que los sistemas de alto nivel dispongan de procedimientos de respuesta a incidentes documentados y probados.
- RGPD y LOPDGDD: Establecen plazos de notificación de brechas de datos personales (72 horas a la autoridad de control) que los playbooks deben respetar.
- Directiva NIS2: La directiva europea de ciberseguridad, en vigor desde 2024, impone obligaciones de notificación de incidentes significativos a las autoridades competentes.
- INCIBE-CERT: El CERT español proporciona guías y servicios de apoyo a la respuesta a incidentes que deben integrarse en los procedimientos de las organizaciones españolas.

Conclusión: Playbooks de respuesta a incidentes
Los playbooks de respuesta a incidentes son documentos vivos que deben evolucionar con las amenazas, la infraestructura y las lecciones aprendidas de cada incidente real. El marco NIST SP 800-61 proporciona una base sólida y probada, pero su verdadero valor se materializa solo cuando los playbooks son específicos para la organización, están actualizados, son conocidos por todo el equipo y se practican regularmente mediante simulacros. La inversión en preparación —desarrollo de playbooks, formación del equipo y ejercicios de tabletop— es la inversión en ciberseguridad con mayor retorno, porque cada minuto que se ahorra durante un incidente real se traduce directamente en menor impacto económico y reputacional.
¿Tu organización necesita playbooks de respuesta a incidentes? En CyberDefensa te ayudamos a diseñar, documentar y probar playbooks alineados con el marco NIST y adaptados a las normativas españolas. Solicita una consulta con nuestros expertos y fortalece tu capacidad de respuesta ante ciberincidentes.
